在Android开发中,经常会使用到缓存,尤其是进行图片加载的时候,我们会先把一个URL对应的图片下载下来,保存到本地文件和内存中,以便下次再次再次用到该图片的时候能够从内存缓存和本地文件缓存中直接读取。这里有一个图片URL映射到缓存key的算法问题,今天在看源码的时候发现volley和picasso的算法不同,这里做一个记录。
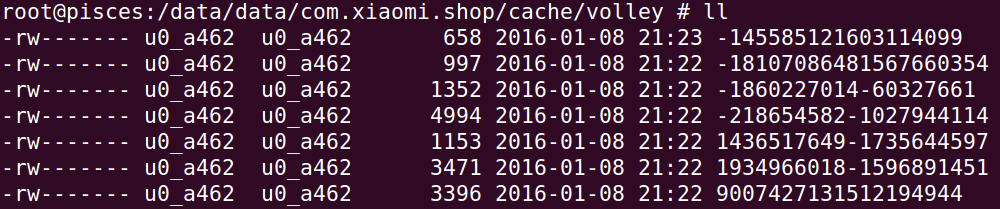
volley使用的是hashcode
|
|
这里有一个特殊的地方,并不是单纯的调用String.hashCode()方法,而是先把url从中间分割成两部分,然后对这两部分分别求其hashCode值,最后把这两个hashCode值分别转化为字符串类型再拼接起来。这里为什么要这么做刚开始不太理解,回忆一下hashCode()方法的实现就明白了。
|
|
hashCode()最终返回的会是字符数组中每个位置的字母的ascii码值再加上上一次hash值乘以31,其实这种算法并不能保证不同的字符串得出的int值是唯一的,乌云上也见过一些攻击正是利用hashCode的逆向算法来做的。把字符串分割两份,分别求hashCode,再转化为字符串拼接到一块,在算法时间复杂度不变的情况下,可以尽可能的降低hash碰撞。
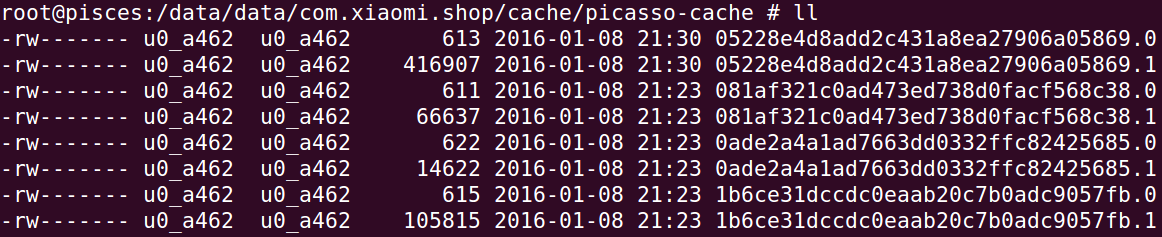
picasso使用的是MD5
|
|
md5算法没什么好说的,在项目中用的比较普遍。